

Melhoria contínua através de Monitoramento, por Kadu Barral, SRE da Klever
Melhoria contínua através de Monitoramento, por Kadu Barral, SRE da Klever
Saiba com o nosso Engenheiro de Site Reliability como ficamos de olhos bem abertos em nosso software para garantir o melhor desempenho e disponibilidade de nossos serviços.


Você provavelmente já ouviu falar sobre as práticas de DevOps e como elas ajudam a fornecer produtos e serviços cada vez melhores. Caso ainda não saiba, te convido a ler este artigo, com uma explicação um pouco mais detalhada sobre o assunto.
Hoje vamos falar sobre Monitoramento, que é uma parte importante do ciclo de vida do aplicativo usado no DevOps.
Durante anos, o Monitoramento era pensado apenas como uma forma de saber quando os problemas aconteciam e tinha apenas uma função: alertar a equipe responsável para fazer os ajustes. As equipes costumavam trabalhar como bombeiros e depois ninguém falava mais sobre isso.
Não achamos que essa seja uma maneira Klever de trabalhar, já que o monitoramento pode nos dar muitos insights. E usar isso apenas durante a solução de problemas é um desperdício de dados e informações preciosas.
Neste artigo, nosso objetivo não é (pelo menos por agora 😉) escrever sobre como implementamos práticas de Engenharia de Confiabilidade de Site (ou Site Reliability Engineer - SRE, como é mais conhecido). Em vez disso, vamos mostrar duas otimizações feitas recentemente pela nossa equipe de DevOps no Ecossistema da Klever, que só foram possíveis através do Monitoramento.
Serviços Distribuídos Globalmente
Um método que usamos para monitorar a disponibilidade de nossos serviços é checar cada um deles com Testes Sintéticos.
O Monitoramento Sintético é uma técnica que utiliza formas de emular o comportamento do usuário para garantir o funcionamento dos sistemas monitorados.
O fluxo de ações do usuário é emulado por meio de outro software, geralmente scripts, e executado repetidamente em intervalos de tempo especificados para medições de desempenho como: funcionalidade, disponibilidade e tempo de resposta.
Em resumo, temos “robôs” em diferentes partes do mundo emulando as funcionalidades do nosso aplicativo, e se algum bot não conseguir completar a tarefa, um alerta é enviado à nossa equipe que então toma medidas proativas.
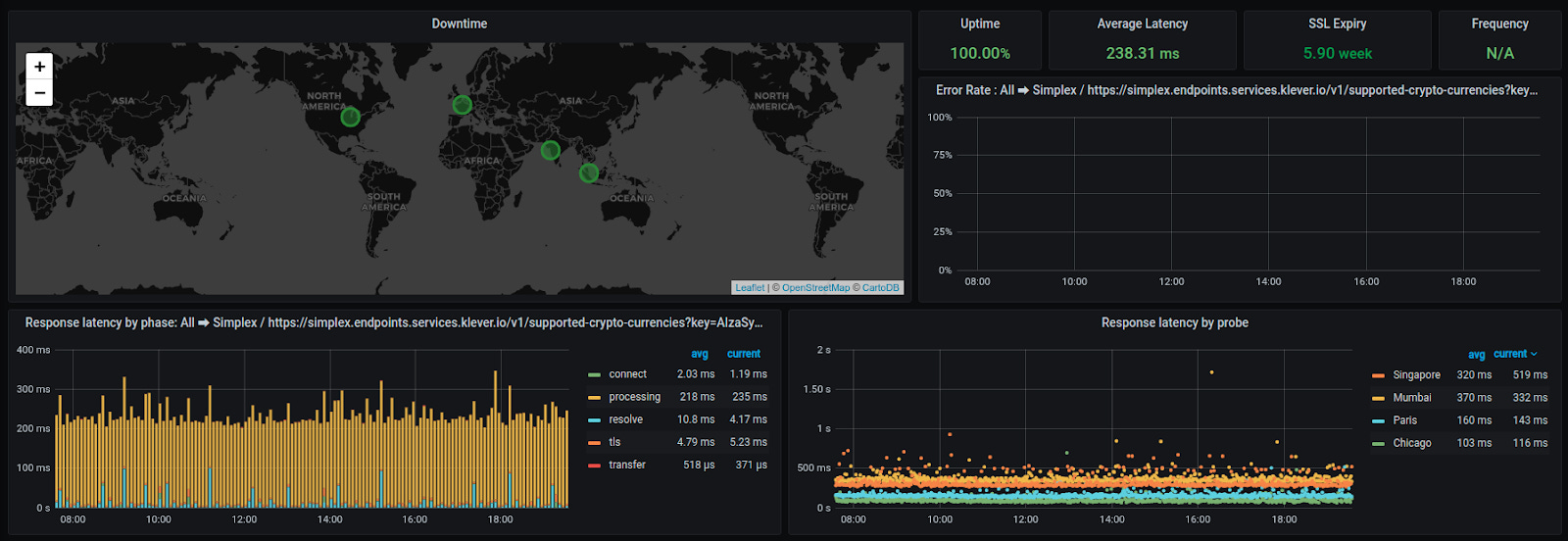
Isso é perfeito para agir no momento em que o problema ocorre, além de nos informar o Tempo de Resposta de nossos serviços em cada local. A ferramenta ainda divide o tempo gasto em cada uma das transações HTTP:
Conectar;
Em processamento;
Resolver;
TLS;
Transferir.
Com esses dados foi possível observar que para algumas localidades as requisições estavam demorando muito em três fases: Conectar, TLS e Transferir.
Solução para o problema de Latência Global
Reduzir o tempo de Conexão e Transferência é um desafio. A solução foi “mover” as aplicações que rodam nos servidores o mais próximo possível dos clientes para reduzir a latência da rede.
Como a Klever tem uma base de usuários e clientes mundiais, replicar nossos serviços para todas as regiões pode ser caro e difícil de manter. Por isso, decidimos migrar o nosso balanceamento de carga tradicional para o GCLB do Google, que fornece balanceamento de carga entre regiões com pontos de presença (PoP) mundiais.
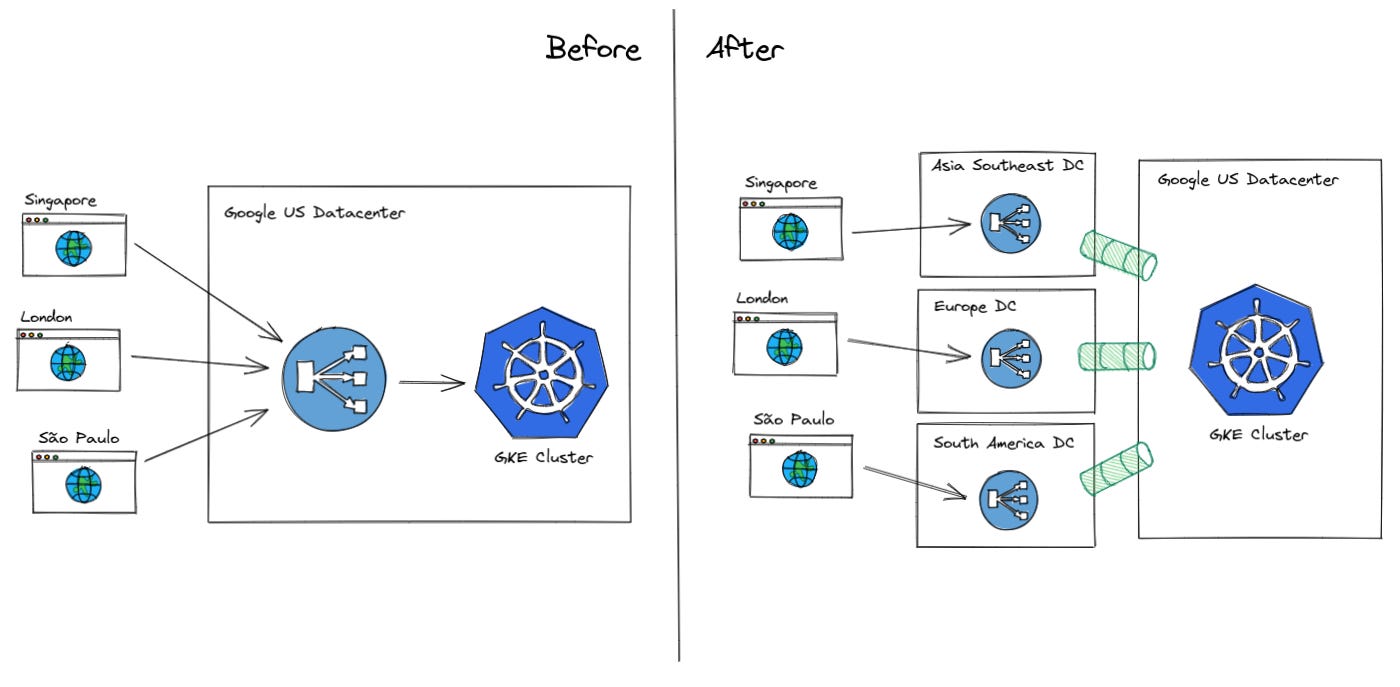
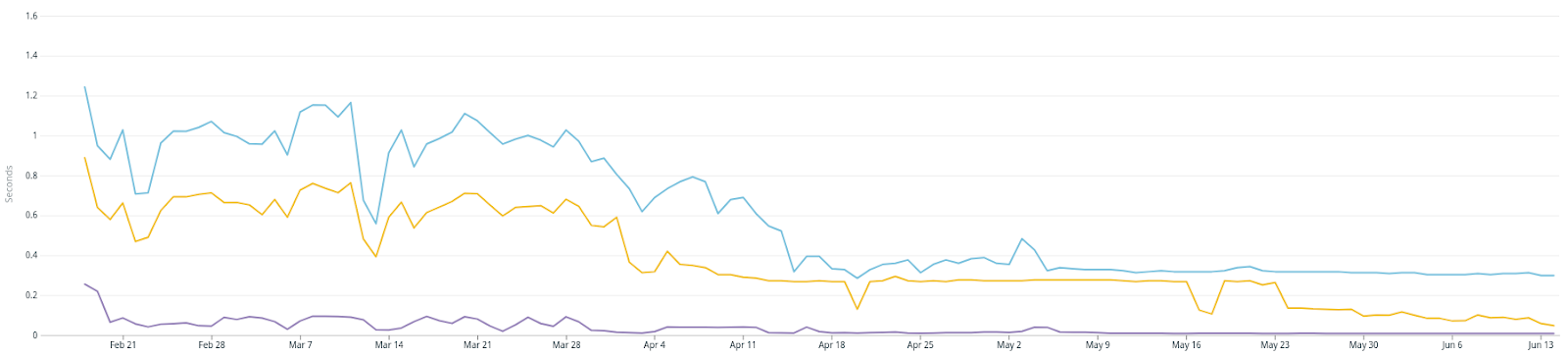
Depois que as conexões são feitas no PoP mais próximo, todo o tráfego para nosso back-end e bancos de dados do Kubernetes viaja na rede interna do Google. Também movemos a terminação TLS de ingress-nginx para a borda do balanceador de carga, para reduzir o tempo de TLS. Com essa mudança, o tempo médio de resposta foi reduzido pela metade, conforme mostrado no gráfico abaixo.
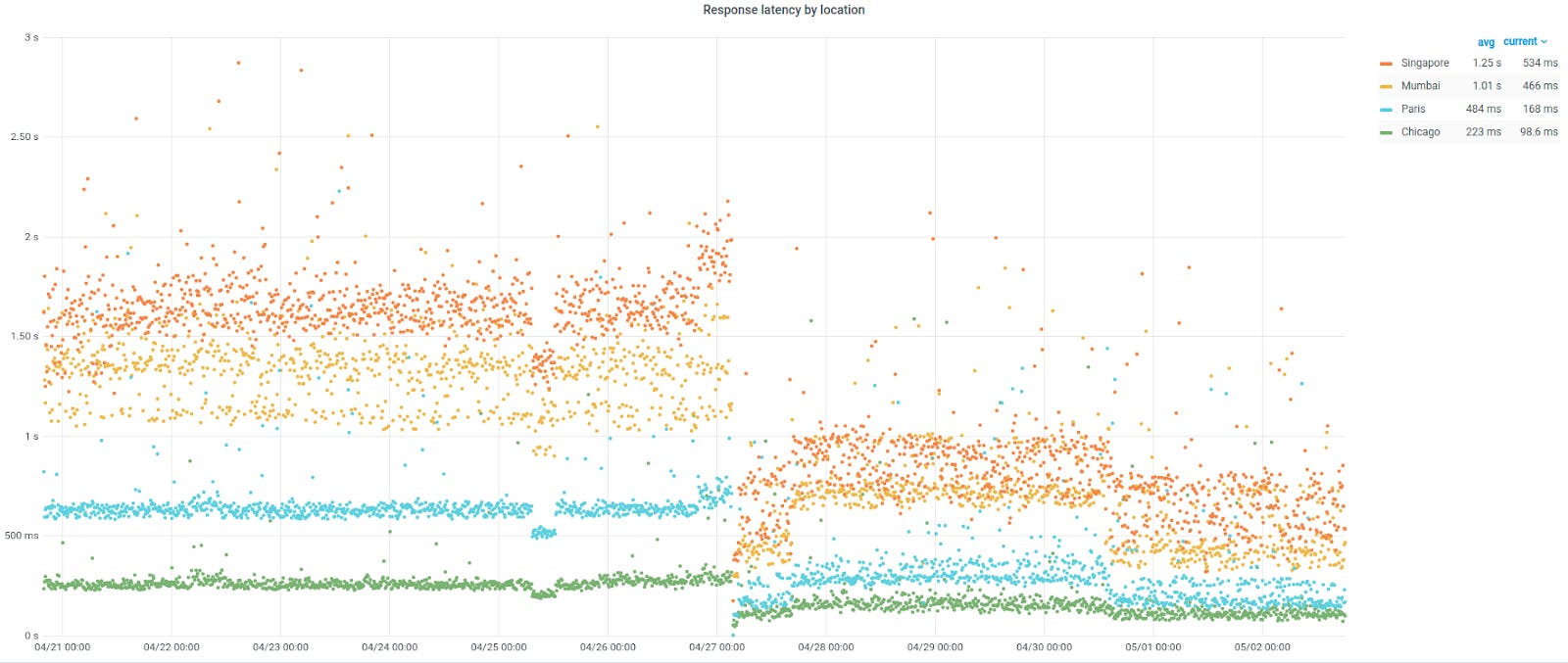
Tempo de resposta na API do Swap
A otimização no tempo de resposta na API do Klever Swap é bem diferente do primeiro exemplo, já que não envolve nenhuma mudança de infraestrutura.
Em nosso monitoramento, foi possível identificar gargalos e, junto com a equipe do Swap, fizemos mudanças no código, resultando em um aumento de 60% no tempo de resposta da API mais chamada pelo método - responsável pela listagem de pares ativos no Swap.
Com uma mudança inteligente e diminuição no consumo do CPU do servidor, foi possível perceber um aumento significativo na velocidade de todos os Swaps da Klever.
Em arquiteturas de software distribuídas, como as usadas pela Klever para atender nossos usuários globalmente, às vezes é difícil encontrar a etapa exata em todo o processo de computação distribuída que é a causa raiz de qualquer potencial lentidão detectada.
Por esse motivo, o rastreamento distribuído é fundamental para entender como uma solicitação se move entre vários serviços, pacotes e componentes de infraestrutura.
Nesse cenário específico, com o rastreio distribuído percebemos que essa API era constantemente chamada, mesmo sem uma transação de Swap, e encontramos uma solução.
Otimizando o tempo de resposta na API do Swap
Este é um caso típico de monólito em que um serviço é responsável por mais de um objetivo. Nossa funcionalidade de Swap é fantástica, fácil de usar e foi um dos nossos primeiros serviços no aplicativo. Naquela época, a funcionalidade que retorna os preços das moedas era construída dentro da API do Swap.
Com a evolução de nosso produto, crescimento de usuários e aumento de moedas disponíveis para Swap, percebemos que era necessário dividir essa funcionalidade em outro serviço. Essencialmente, para separar e distribuir os preços e serviços de troca para tornar todo o recurso do Swap mais rápido, confiável e eficiente.

Após essa alteração, outras telas no aplicativo poderiam consultar os preços atuais sem afetar o desempenho geral do Swap e fomos capazes de dimensionar o serviço separadamente, dependendo da demanda.
Conclusão
Neste artigo, apresentamos dois exemplos de como o monitoramento contínuo de nossos serviços nos ajuda a trazer produtos de alta qualidade e em constante evolução para a comunidade Klever.
É claro que o monitoramento envolve muito mais do que mostramos aqui hoje e o básico também é muito importante:
Garantir o bom funcionamento de todos os serviços da Klever é o nosso propósito.
Uma boa estratégia de monitoramento reduz nosso MTTA e MTTR e permite que nossa equipe permaneça 24 horas por dia, 7 dias por semana, distribuída globalmente, sempre ciente de possíveis problemas e garantindo escalabilidade por meio de medidas proativas. Bruno Campos, nosso CTO, falou um pouco sobre isso em seu artigo aqui.
Manter o rastreamento de microsserviços é um desafio em Arquiteturas de Software Distribuídas e o Monitoramento precisa ser sempre contínuo para o progresso da equipe de DevOps na Klever. Mas isso é um assunto para outra hora!
Sinceramente,
Kadu Relvas Barral
Site Reliability Engineering da Klever
Kadu tem mais de 15 anos de experiência profissional em TI e passou os últimos 10 anos trabalhando em seguradoras, telecomunicações e empresas financeiras, tentando encontrar o que estava quebrado em seus sistemas antes que outros descobrissem. Maratonista nas horas vagas, gosta de correr e de manter os aplicativos sempre em funcionamento.
Baixe o Klever App
